Neuroscience – primate visual system

Share
Share article via
Or copy link
Biological systems and evolution
When discussing biological inspirations for designing the artificial visual system, we need to keep in mind one important fact – the biological visual system (as any other sensory system) has obtained its current shape in the process of evolution. This puts both some requirements on and constraints on the exact functioning of the system. First, the primary “goal” of adaptations is to increase the survival chance of an animal in its current environment. Secondly, evolution “prefers” sub-optimal solutions, whereby “sub-optimal” mean solutions that are sufficient for an animal to survive long enough to reproduce (and raise offspring until they can reproduce). Evolution is also unable to build any system from scratch in a few generations – in a short timescale, it can only slightly modify what it already has through small, non-lethal mutations (therefore even though dolphins readapted to living in the water, they have never acquired the ability to breathe underwater).
Basic features
Biological vision is a cognitive system and as such, it has to not only allow object recognition or face discrimination, but it needs to continuously interpret the visual scene in order to increase survival chance of an animal. This includes searching for food, distinguishing between conspecifics, subconscious monitoring of the environment for predators and other threats, visual guidance of precise hand/mouth motion (processing of distance information), correction of visual input for self-motion, integration of visual information with auditory and somatosensory input, understanding object constancy, motion processing.
Here are some features of the primate visual system that help it fulfill the above-listed functions. In the following subsections, we will discuss how they contribute to the high performance of the primate visual system.
- · Stereoscopic vision
- · Two types of photoreceptors – rods and cones
- · Hierarchical organization of visual processing
- · Selective data processing
- · Attention-governed processing
- · Neurons organized into columns and hypercolumns
- · Population coding and feature maps
- · Processing data in the temporal dimension
- · Universality
- · Continuous learning
- · Hierarchical learning
- · Novelty seeking
Stereoscopic vision
Primates not only have binocular vision (two eyes), but both of their eyes point forward, resulting in partial overlap (approx. 60 degrees) of the visual fields seen by the eyes. This overlap allows computing depth (distance) based on the relative shift of the object’s image formed on the left and right retina. This depth estimation helps perform precise, visually-guided motions or assess the distance of the next tree branch. However, it may also be useful in object recognition, especially for the separation of objects (e.g. a predator) from the background – when an object’s color/texture is similar to the background, it is more difficult to extract the object’s contours. Then other cues such as lighting and depth can be used to find object boundaries.
Two types of photoreceptors – rods and cones
There are 2 types of photoreceptors in the primate retina: cones and rods. Cones can be further divided into 3 types, based on their absorption spectrum: short-wavelength (S or „blue”), medium-wavelength (M or „green”), and long-wavelength (L or „red”; not in all primates), which cover the range 400-700 nm (i.e. „visible” light. They have low sensitivity to light, thus they operate best in daylight and relative activations of different cone types allow them to distinguish between different colors, allowing them to see subtle changes in color. However, animals need the ability to detect predators in various lighting conditions. For that reason, there is another type of photoreceptor – a rod. Rods are much more sensitive to light, predominantly to short-wavelength light: violet to cyan, whose intensity is lower at sunrise and sunset. They are also useful under starlight, but in daylight, they get saturated, hence unable to transmit any useful information. Such a design allows the visual system to operate both in daylight and in poor lighting conditions which, again, helps to avoid predators.
Hierarchical organization of visual processing
The visual system in the primate brain can be roughly divided into two hierarchical parts: the early visual system and the higher-order visual system (of course it is an arbitrary division). The early visual system consists of structures such as the retina, lateral geniculate nucleus (LGN), primary visual cortex (V1), secondary visual cortex (V2), and a few other cortical regions: V3, V4, and MT cortical areas (as well as a few other subcortical regions that were not mentioned here). These regions seem to be predominantly focused on extracting some universal features from the image, such as edges, colors (color constancy), brightness, binocular disparity (correlate of depth), motion direction, corners, surface curvature, etc. They do it retinotopically (i.e. maintaining spatial relationships the same as in the retinal image). The higher-order visual system is localized in the inferior temporal gyrus (IT) and in the posterior parietal cortex. Its main goal is to use the spatial and temporal correlation between those features, to recognize complex objects such as animals, faces, etc., to distinguish between similar individual objects of the same category, perform mental manipulation, etc. It is somewhat similar to the standard convolutional neural network architecture, consisting of two parts: convolutional layers playing the role of feature extractors and fully-connected layers serving as a classifier. Similar, yet largely simplified organization. It is therefore worth seeing what inspiration we can find in the hierarchy of the biological visual system.
While the first stage (i.e. feature extraction) is computationally heavy – one needs to process information from the whole visual field (or at least of the whole fovea – i.e. the central part of the visual field), it is also much simpler – there is only a limited number of basic features that need to be extracted. Moreover, it is most likely possible to pre-train that early visual cortex – its representations seem to be formed in the early development of an animal and stay relatively stable later on. Plus its major target areas are the areas within the higher-order visual system.
The latter (higher-order visual system) needs to encode an enormous number of complex objects, therefore object recognition could be interpreted as a sparse search algorithm, where only a small fraction of the IT cortex is activated by a specific object (e.g. fusiform face area – by a face of a known person). Due to that sparsity, it can be optimized in multiple ways using architectures other than standard artificial neural networks – e.g. search trees or clustering algorithms using data routing. Object representations in those areas need to be formed (trained) in a continuous way in order to contribute to a fully functional cognitive system, able to adjust its behavior based on previous experiences. Furthermore, the higher-order visual system needs to interact with multiple other cortical areas such as the hippocampus, prefrontal cortex, areas involved in visuo-auditory integration, visuo-somatosensory integration, spatial memory (entorhinal cortex and hippocampus), etc.
Selective data processing
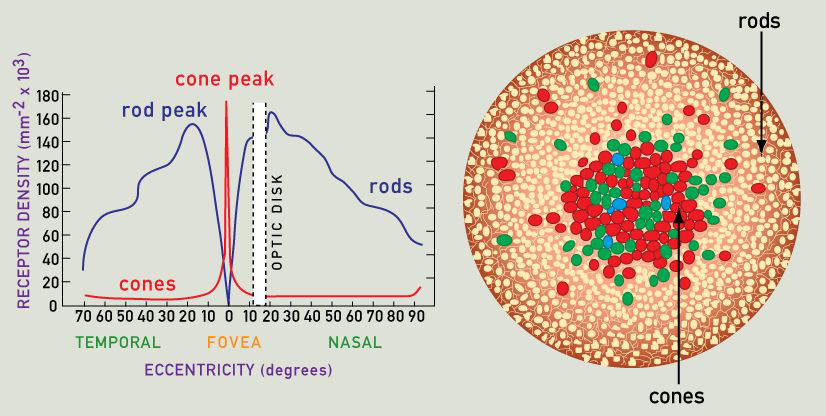
Primate visual system does not process the whole visual scene at once – due to its biological limitations. Rods and cones are not evenly distributed across the retina. Cones are primarily located in the fovea and parafoveal regions (in the center of the retina). As a result, only a small fraction of the retina can process visual input in high spatial resolution, whereas peripheral vision is much more blurred. Rods, on the other hand, are almost absent in the fovea, but located more peripherally, allowing higher sensitivity to potential predators in poor lighting conditions. Since only a small fraction of the retina can be used for fine object recognition, the visual system had to find another way to process the whole visual field. The answer was to use saccadic eye movements between salient elements of the object/visual scene – this way the whole visual scene is integrated from multiple patches, processed in high spatial resolution sampled over the course of a few hundred milliseconds to a few seconds (maybe even more – depending on the anxiety level as well as the complexity and familiarity of the scene).
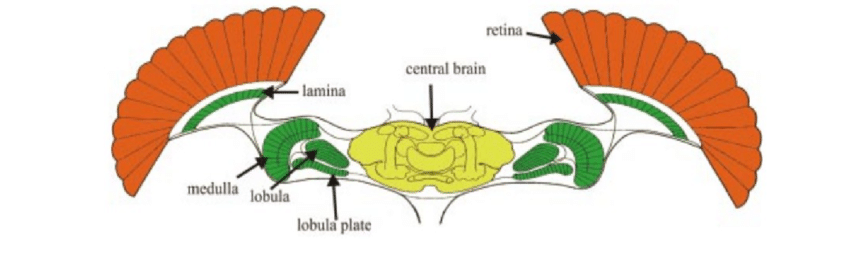
That makes fine visual processing slower, but at the same time it allows the network responsible for visual processing to be quite small – unlike in flying invertebrates (e.g. fruit fly), which have roughly constant spatial resolution across the retina, but their visual system is huge compared to the whole brain. The retina (in red) itself is bigger than the rest of the brain, whereas higher-order visual areas (in green) are similar in size to the rest of the brain (in yellow). Although advantageous to flying insects, whose speed is high compared to their body size, such a big visual system consumes a lot of energy. Plus, the primate visual system is specialized in fine recognition of complex objects at multiple size scales, therefore it needs to be more flexible than that of a fruit fly.
Since the biological visual system is unable to process the whole visual scene in high detail at once and it needs to perform multiple saccadic eye movements, there need to exist some mechanisms responsible for choosing the most important visual stimuli to process at the moment (i.e. the stimuli towards which gaze should be shifted). It turns out that the visual system, eye movement, and attention are tightly coupled. The attention system can be divided into two major parts: bottom-up attention and top-down attention.
The first one is active all the time and searches for salient stimuli (food, predators, or other unexpected stimuli) in the visual field. It is a passive, sub-conscious system, mostly concerned with ensuring animal safety, therefore it needs to work fast – it is mostly limited to low-level brain areas, such as the superior colliculus (SC) and primary visual cortex (V1) and it is most likely predominantly use low-spatial-resolution information from the peripheral vision. When a salient stimulus is detected, it may cause the animal to stop its current action and shift its gaze to that stimulus for more precise processing.
The latter (top-down) attention system is involved in the volitional processing of a visual scene, e.g. active search for a specific object or shifting gaze from one feature of a perceived object to another feature. Top-down attention seems to be dependent on higher-order visual (area V4 and inferior temporal gyrus, IT – for object completion) and associative (e.g. prefrontal cortex, PFC; involved in decision making and posterior parietal cortex, PPC; involved in multisensory integration) areas. It works much slower and uses higher-order and more abstract representations and is performed through feedback connections, starting in those high-order areas and targeting progressively lower levels of the visual cortex, until reaching V1 or LGN. Such a dual attention system allows the animal to pay attention to details of objects, while constantly monitoring the environment for potential danger.
Structural organization
Neurons organized into columns and minicolumns
Neurons in the cerebral cortex are functionally organized into so-called cortical columns and minicolumns. Columns and minicolumns are basically oriented perpendicularly to cortical surface groups of neurons that share similar functions (e.g. encode a similar feature/stimulus or represent a similar portion of the visual field). This makes representations more organized – while all of the minicolumn’s neurons are sensitive to one or more common stimuli, single neurons can also respond to different sets of stimuli. This way we can obtain e.g. a minicolumn sensitive to an edge inclined at an angle of 30 degrees, irrespective of other features of the edge. Some neurons within that minicolumn may be only sensitive to edges between red and green areas of the image, or between blue and yellow, while others may only respond to depth-defined edges. However, the minicolumn as a whole would still respond to all edges of that specific orientation.
Cortical columns are higher-order organizational structures, consisting of multiple minicolumns. While a single minicolumn of the visual cortex represents a single feature (e.g. an edge oriented at a given angle), a single column represents the whole set of all possible features at a specific location in the visual field. A cortical column encodes information as a sparse activation of a specific subset of minicolumns (e.g. some representing the edge orientation, some representing motion direction, and some representing the color of the feature).
Population coding and feature maps
Features represented by cortical minicolumns form a continuous map (at least in early visual areas), i.e. neighboring columns tend to encode similar features. For example, if a minicolumn in V1 encodes an edge inclined at 30 degrees, the neighboring columns may be sensitive to edges inclined at 25 or 35 degrees, but not at 90 degrees. Visual cortical columns do show precise coding (i.e. binary detection of their preferred stimulus, such as edge inclined at 30 degrees). They use coarse coding instead – every column has a preferred stimulus (e.g. edge inclined at 30 degrees) that evokes maximal activation but can also be activated to a lower degree by suboptimal stimuli (e.g. edge inclined at 25 or 35 degrees). Neighboring columns also tend to innervate partially overlapping groups of neurons in higher-order visual areas. All of the above features of columns contribute to columns’ population coding – that is a neuron, which needs information about line orientation receives it as combined activation of a group of neighboring columns, which drastically increases the potential capacity of the network.
Processing data in the temporal dimension
Many standard artificial networks used for object classification operate on single images. And when we feed them some video, they treat it as a series of unconnected images. This is due to the linear architecture of the network and the lack of any short-term memory. However, a biological visual system functioning in such a way would be poorly adapted to the natural environment. Processing of the current visual scene in the context of the past visual scenes is essential for such phenomena as motion perception, object constancy, estimation of distance based on motion parallax, visually guided self-movement, correction for self-movement, etc. A full understanding of the surrounding world requires temporal integration of visual information. Otherwise hunting, avoiding predators, and exploring the environment would be impaired.
Temporal integration of information in the brain is possible thanks to multiple mechanisms. The most important seems to be the following:
1. Temporal summation of postsynaptic potentials in the soma (cell body) of the neuron due to:
slow changes in membrane potential (well, at least in the subthreshold regime it’s slow), especially the slow repolarization, when membrane potential returns to its resting value varying distance of synapses from the soma, which makes some inputs reach the soma faster than the others
2. Synaptic delay – since most of the synapses in the brain are chemical (i.e. based on the secretion of neurotransmitters into the synaptic cleft), there is a significant delay at every single synapse caused by the dynamics of synaptic vesicles docking, opening, neurotransmitter diffusion, dynamics of postsynaptic receptors opening, etc. It may seem to be a bad choice (since there exist “electrical synapses” as well), but the delay is still much lower than the timescale of most salient changes in the environment. Additionally, thanks to synaptic delay one can differentiate the arrival time of some signals even more – by sending some inputs directly, while others indirectly – even if the path is of the same length, the one that has three synapses will arrive at least 1.5 ms later – it is usually estimated that synaptic delay takes 0.5 ms, but one needs to take dendritic transmission and action potential generation into account.
3. Feedback connections. Due to finite speed of action potential generation through axons and synaptic delay, the feedback information delivered from higher-order areas through feedback connections may in many cases be treated not only as a correcting signal computed using a broader context but also as a predictive signal. That is since the original input to the lower-order area might have changed by the time the feedback signal arrived, it is likely that the connections learn to reflect the prediction of that change.
Universality of representations
Animals in the real world need to be able to create visual representations of a huge number of objects (object classes) and then associate them with proper behavior (feed, fight, avoid, mate, etc.), therefore the representations encoded in the visual system should be as universal as possible – at least low-order visual areas should encode some universal features, such as oriented lines, angles, motion direction, surface curvature, etc., while higher-order visual areas need the ability to encode any object using spatial relations between those universal features. For example, some psychological theories of vision assume that object recognition may be based on „geons” (geometric ions), which are simple 2D or 3D shapes such as a rectangle, circle, brick, sphere, cone, etc. Their main advantages are:
- · A limited number of required geons (usually about 40 basic geons)
- · Large representational capacity – e.g. by combining 2 out of 24 geons we can build about 1 million 2-geon objects
- · Viewpoint-invariance – a geon looks almost the same from any perspective, which makes its recognition much easier
- · On the other hand some recent research shown that recognition of at least some objects is not viewpoint-invariant, e.g. faces, which activate different regions, based on the orientation (e.g. frontal or from the side)
- · Stability – geons are robust to occlusion and noise
Learning in the brain
Unsupervised learning
Animal brains do not receive any labeled data to work with. Sensory systems need to make sense of the raw input using similarity search (and grouping representations of similar objects together) and association of non-similar objects which correlate spatially or temporally. This is likely achieved using primarily the two learning rules:
Learning the statistics of the environment. By learning statistics we should understand learning such a representation of the stimuli that reflects their probability of occurrence and allows efficient and accurate distinguishing of the most common stimuli. For example, when processing the depth of the scene, we may notice that objects in the lower half of the visual field tend to be localized much closer (on average) than the stimuli in the upper half of the visual field. Well, it is true when looking straight ahead or looking down – in such cases the total distance in the lower half is limited by the height of the observer; at the same time in the upper half, we can often see treetops, mountains on the horizon, etc. It is, therefore, logical to build such a representation of the lower half of the visual field that allows for more precise distinguishing the exact depth at very small distances, but not the precise as precise at a higher distance, whereas to tune the upper half representations for distinguishing depth at higher distances. This is consistent with human perception – people tend to perceive objects in the lower half of the visual field as located closer than they really are, while objects in the upper half are perceived to be farther away than in reality.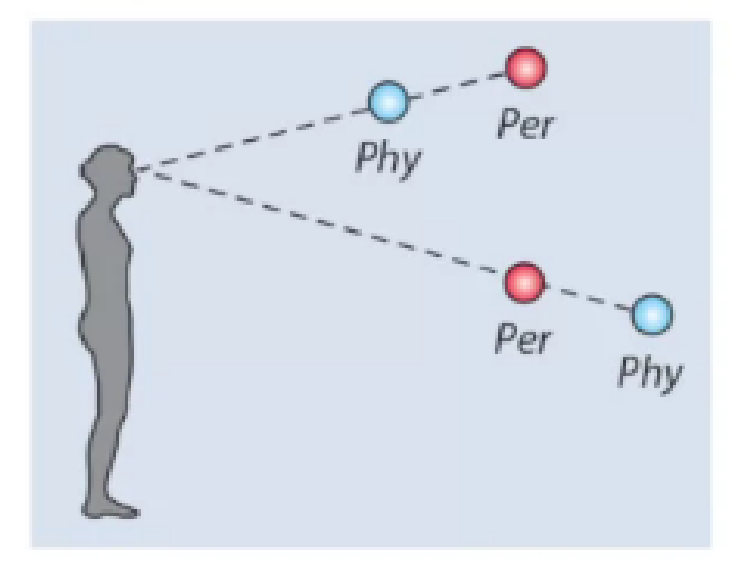
Self-supervised learning, is achieved by both:
Bottom-up, top-down and lateral voting – processed information in the brain flows in both directions: first, the lower-order areas send their first guess on the stimulus through feedforward connections, then the lateral input from neighboring neurons as well as feedback input from higher-order areas arrive and may verify the initial guess since they deliver some broader context (either spatial or temporal terms, or both). For example processing of illusory edges may be achieved this way – the initial guess of a neuron may be that there is no edge at that point, but after it receives information from its neighbors and feedback information that both agree that there should be an edge here, it may change its guess so that the network receives spatial agreement on that portion of the visual scene
Integration of multisensory information. In the environment, there are multiple non-accidental correlations between visual, auditory, olfactory, somatosensory, etc. stimuli. For example, we can often tell whether the fruit is sweet just by looking at it. Thin pointy objects are sharp. Different species of animals tend to produce characteristic sounds. These correlations may be used as a learning signal – for example in a case when the visual system is not sure, whether the animal is a dog or a cat, but a second later the animal barks. Then the highly certain prediction from the auditory cortex gets integrated in the associative cortex and it predicts: “it’s a dog”. The decision is next sent down to the visual cortex to modify its initial guess and possibly learn new features useful for distinguishing dogs from cats.
Continuous learning
The animal brain cannot afford to have fully separate „training” and „usage”/”inference” phases, it needs to operate all the time to survive (well almost all the time – except for short periods during the sleep). Therefore it needs a much more sophisticated system, allowing it to learn on the fly, and being able to instantly reuse newly acquired information (e.g. appearance of a predator encountered a moment ago – in case it reappears a little later). Indeed the brain’s learning system happens to be quite complex.
First, while learning of early sensory representations seems to be simple and straightforward – e.g. neurons in V1 are directly trained (update their synaptic strengths) in early development (prenatally through coordinated activations of groups of neurons or shortly after birth, while animal observes its environment), when the animal is still helpless. Or we could say that the animal is helpless at that early stage, because its sensory representations are still not fully developed, making it impossible to demonstrate higher cognitive functions, such as decision making. If these early sensory representations are universal and can be used to encode features of any object, plus are essential for higher cognitive functions, then they may indeed be trained this way (i.e. by directly modifying their synaptic weights, similarly as in – since learning those early representations fast seems the best thing to do.
However, the situation changes when it comes to higher cognitive functions. A more developed animal (a „teenager” or a mature one), which has already achieved some degree of brain development needs the above-mentioned ability to quickly encode new information and instantly reuse it. But short exposure to a new stimulus or new context may not be sufficient to create a generalizable representation due to high levels of noise, partial occlusion, random correlations with other stimuli, etc. Therefore a cognitive system needs a multi-stage memory system, consisting anatomically (as for declarative memory) of two major parts: the hippocampus and cerebral cortex. New information is first encoded in the hippocampus so that it can be temporarily stored for later use. Next, during sleep in the process of memory consolidation hippocampal neurons, associated with objects and situations encountered during the day, get reactivated, which helps form cortical representations for long-term storage, while removing unnecessary information and noise. One of the mechanisms involved in consolidation may be the strengthening of direct connections between cortical neurons that were activated by a specific stimulus (e.g. representation of a person’s face with the representation of their new outfit – so that in the future we can use the outfit to speed up recognition). Before consolidation, the only bridge connecting those two representations strong enough to induce memory recall would be the hippocampus, whereas after consolidation their direct connection could be so strong that no bypass is needed anymore. In this context, the hippocampus could be interpreted somewhat as a hashing function choosing which neurons/columns should be connected with each other.
Hierarchical learning
Artificial neural networks trained using gradient descent learn in a top-down fashion (that is the weight updates are the greatest in the last layers of the network and get weaker, as the error is propagated backward) and thus a large portion of the learning is determined by the initial randomness of the last layer. The brain seems to take a very different approach here: it starts the learning from the bottom and progressively learns higher- and higher-order areas. In the process of brain development, there are multiple control processes. Initially, there are much more neurons and much more connections (both in terms of local synapses and of axon collaterals), and the unuseful ones get eliminated as the development progresses. Another important process is the myelination of useful long-distance axons. Myelin sheath increases the speed of information propagation through axons, provides nutrients to axons, etc. Myelination is an energy-intensive and irreversible process (once the axon gets myelinated, it’s not able to function without the myelin – for more information see disorders such as multiple sclerosis or amyotrophic lateral sclerosis), therefore it needs to be initiated only by axons that have proven to be useful. In the human brain, myelination starts in subcortical regions and primary sensory areas (e.g. primary visual area) and progresses to higher-order areas. However, it starts in the prenatal life, but the process lasts for many years and is often correlated with developmental milestones, such as learning to walk at the age of two years old. The connections between higher-order associative cortices, such as the prefrontal cortex (involved in planning and decision-making) get myelinated as the last ones – in the third decade of life. This scheme, where the lowest levels of the network finish development first (and probably drastically lower their plasticity) suggests a learning algorithm very different from gradient descent and other supervised methods. In fact, newborns are able to detect and follow faces in the environment (and show quite a large interest in faces) even though they have never seen a face before, and have not learned to recognize people by faces. Yet their visual representations of basic facial features are developed enough to detect faces. Therefore we may expect that the brain uses some local plasticity rules in order to find the best representations at each stage of information processing (to kind of “cluster” representation of similar stimuli together, while moving away representations of unlike stimuli). And only after that representation is useful and stable enough, it can be successfully used in training some higher-order areas.
Novelty seeking
As already mentioned, newborns display a significant interest in human faces and tend to spend much time staring at them. This is another feature characterizing many living beings – curiosity. At some point in development, many animals get interested in exploring the environment, with a large emphasis on novel and unexpected objects. This helps learn new representations of objects as well as improve the model of the world (i.e. that objects with specific visual features tend to be e.g. more heavy, sharp, or squishy than others, some are edible, some can be used to crack nuts, etc.). Curiosity and novelty-seeking can facilitate learning by focusing on those objects that are unfamiliar and poorly understood, instead of processing those same objects all the time (even though it does not give any new knowledge – or in other words, does not improve animal adaptation and does not increase its survival chance). For this reason, we may expect that having some kind of curiosity would be advantageous for an agent with limited computing power, learning in a continuous fashion (i.e. with a limited number of examples, no separate training phase, etc.).
